Breaking the Code: Security Assessment of AI Code Agents through Systematic Jailbreaking Attacks
Code-capable LLM agents are increasingly embedded in software workflows, raising the question of how robust they are to adversarial misuse. We present JAWS-BENCH, a benchmark for systematically assessing the security of AI code agents across empty, single-file, and multi-file workspace regimes, and show that wrapping an LLM in an agent substantially increases its vulnerability to jailbreaking attacks.
CiteEval: Principle-Driven Citation Evaluation for Source Attribution
Citation quality is crucial in information-seeking systems. We introduce CiteEval, a principle-driven citation evaluation framework that assesses fine-grained citation quality within a broad context including the full retrieval context, user query, and generated text; CiteBench, a multi-domain human-annotated benchmark; and CiteEval-Auto, model-based metrics that correlate strongly with human judgments.
Using Natural Language Explanations to Rescale Human Judgments
Verifying political claims is a challenging task, as politicians can use various tactics to subtly misrepresent the facts for their agenda. Existing automatic fact-checking systems fall short here, and their predictions like “half-true” are not very useful in isolation, since it is unclear which parts of a claim are true and which are not. In this work, we focus on decomposing a complex claim into a comprehensive set of yes-no subquestions whose answers influence the veracity of the claim. We present CLAIMDECOMP, a dataset of decompositions for over 1000 claims. Given a claim and its verification paragraph written by fact-checkers, our trained annotators write subquestions covering both explicit propositions of the original claim and its implicit facets, such as asking about additional political context that changes our view of the claim’s veracity. We study whether state-of-the-art models can generate such subquestions, showing that these models generate reasonable questions to ask, but predicting the comprehensive set of subquestions from the original claim without evidence remains challenging. We further show that these subquestions can help identify relevant evidence to fact-check the full claim and derive the veracity through their answers, suggesting that they can be useful pieces of a fact-checking pipeline.
Improving Cross-task Generalization of Unified Table-to-text Models with Compositional Task Configurations
Verifying political claims is a challenging task, as politicians can use various tactics to subtly misrepresent the facts for their agenda. Existing automatic fact-checking systems fall short here, and their predictions like “half-true” are not very useful in isolation, since it is unclear which parts of a claim are true and which are not. In this work, we focus on decomposing a complex claim into a comprehensive set of yes-no subquestions whose answers influence the veracity of the claim. We present CLAIMDECOMP, a dataset of decompositions for over 1000 claims. Given a claim and its verification paragraph written by fact-checkers, our trained annotators write subquestions covering both explicit propositions of the original claim and its implicit facets, such as asking about additional political context that changes our view of the claim’s veracity. We study whether state-of-the-art models can generate such subquestions, showing that these models generate reasonable questions to ask, but predicting the comprehensive set of subquestions from the original claim without evidence remains challenging. We further show that these subquestions can help identify relevant evidence to fact-check the full claim and derive the veracity through their answers, suggesting that they can be useful pieces of a fact-checking pipeline.
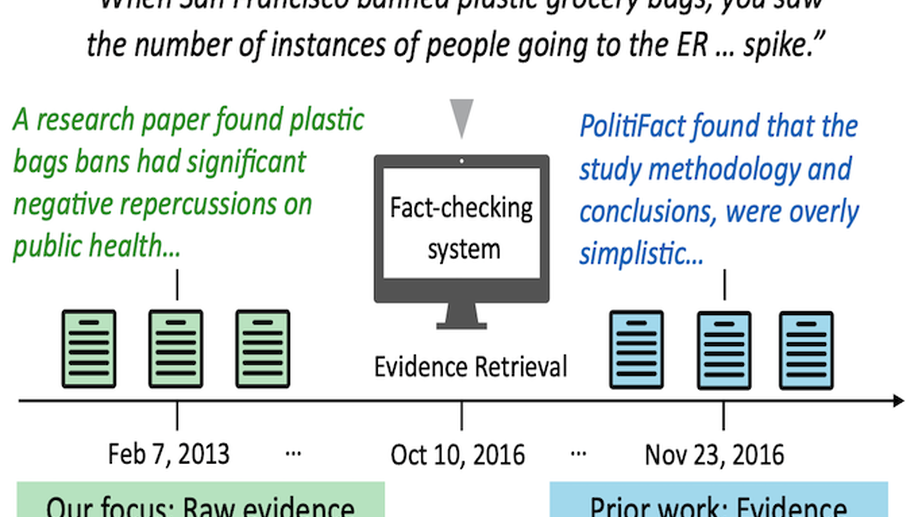
Complex Claim Verification with Evidence Retrieved in the Wild
Evidence retrieval is a core part of automatic fact-checking. Prior work makes simplifying assumptions in retrieval that depart from real-world use cases: either no access to evidence, access to evidence curated by a human fact-checker, or access to evidence available long after the claim has been made. In this work, we present the first fully automated pipeline to check real-world claims by retrieving raw evidence from the web. We restrict our retriever to only search documents available prior to the claim’s making, modeling the realistic scenario where an emerging claim needs to be checked. Our pipeline includes five components: claim decomposition, raw document retrieval, fine-grained evidence retrieval, claim-focused summarization, and veracity judgment. We conduct experiments on complex political claims in the ClaimDecomp dataset and show that the aggregated evidence produced by our pipeline improves veracity judgments. Human evaluation finds the evidence summary produced by our system is reliable (it does not hallucinate information) and relevant to answering key questions about a claim, suggesting that it can assist fact-checkers even when it cannot surface a complete evidence set.

Generating literal and implied subquestions to fact-check complex claims
Verifying political claims is a challenging task, as politicians can use various tactics to subtly misrepresent the facts for their agenda. Existing automatic fact-checking systems fall short here, and their predictions like “half-true” are not very useful in isolation, since it is unclear which parts of a claim are true and which are not. In this work, we focus on decomposing a complex claim into a comprehensive set of yes-no subquestions whose answers influence the veracity of the claim. We present CLAIMDECOMP, a dataset of decompositions for over 1000 claims. Given a claim and its verification paragraph written by fact-checkers, our trained annotators write subquestions covering both explicit propositions of the original claim and its implicit facets, such as asking about additional political context that changes our view of the claim’s veracity. We study whether state-of-the-art models can generate such subquestions, showing that these models generate reasonable questions to ask, but predicting the comprehensive set of subquestions from the original claim without evidence remains challenging. We further show that these subquestions can help identify relevant evidence to fact-check the full claim and derive the veracity through their answers, suggesting that they can be useful pieces of a fact-checking pipeline.

Can NLI Models Verify QA Systems' Predictions?
To build robust question answering systems, we need the ability to verify whether answers to questions are truly correct, not just good enough in the context of imperfect QA datasets. We explore the use of natural language inference (NLI) as a way to achieve this goal, as NLI inherently requires the premise (document context) to contain all necessary information to support the hypothesis (proposed answer to the question). We leverage large pre-trained models and recent prior datasets to construct powerful question converter and decontextualization modules, which can reformulate QA instances as premise-hypothesis pairs with very high reliability. Then, by combining standard NLI datasets with NLI examples automatically derived from QA training data, we can train NLI models to judge the correctness of QA models’ proposed answers. We show that our NLI approach can generally improve the confidence estimation of a QA model across different domains, evaluated in a selective QA setting. Careful manual analysis over the predictions of our NLI model shows that it can further identify cases where the QA model produces the right answer for the wrong reason, or where the answer cannot be verified as addressing all aspects of the question.

Understanding Dataset Design Choices for Multi-hop Reasoning
Learning multi-hop reasoning has been a key challenge for reading comprehension models, leading to the design of datasets that explicitly focus on it. Ideally, a model should not be able to perform well on a multi-hop question answering task without doing multi-hop reasoning. In this paper, we investigate two recently proposed datasets, WikiHop and HotpotQA. First, we explore sentence-factored models for these tasks; by design, these models cannot do multi-hop reasoning, but they are still able to solve a large number of examples in both datasets. Furthermore, we find spurious correlations in the unmasked version of WikiHop, which make it easy to achieve high performance considering only the questions and answers. Finally, we investigate one key difference between these datasets, namely span-based vs. multiple-choice formulations of the QA task. Multiple-choice versions of both datasets can be easily gamed, and two models we examine only marginally exceed a baseline in this setting. Overall, while these datasets are useful testbeds, high-performing models may not be learning as much multi-hop reasoning as previously thought.